JS页面加载window.onload与DOMReady的区别
描述
很多时候为了想要在页面初始化的时候运行一段JS代码,都会这么写:window.onload,到底这个函数是什么时候开始运行的呢,和DOMReady有什么区别?往下看
- window.onload:在页面所有元素加载完了之后才开始执行,包括页面中所有的图片或者多媒体元素,加载时间很长,延迟也很多
- DOMReady: 从字面上看能理解出来,在DOM树加载完成之后就在开始执行,并不关心节点里的内容是什么东西。延迟小
相比之下。用DOMReady更合适初始化工作
实现方法
1.window.onload
一般是这么写:
window.onload=function(){
//code
}2.DOMReady
把函数入口放在html底部就可以
...
<script type="text/javascript">unit();</script>
</body>
</html>主流的几个js框架也能实现
- JQuery:
$(document).ready()=function(){
//code
}- YUI
YAHOO.util.Event.onDOMReady()=function(){
//code
}学习笔记(二)之Html5 Web 存储
1.Html5 Web 存储(localStorage与sessionStorage)
为什么使用Storgae
- cookie:限制数据大小为4k,而且不支持组织持久数据,并且每次发送同源的请求时,cookie数据都会跟着一起发过去。
- Storage对于不同浏览器分配的大小不同,chrome中是5M,主流浏览器一般都在5-10M,这里的大小限制是指一个子域最大课使用的空间。这可比cookie好用太多了,数据存在本地,这就意味着可以离线使用啊,很赞对不对
注意:localStorage不能设置有效期,写入之后永远存在,可以使用clear()清除,我设想是可以在写入时就定义一个访问次数字段,每次读取时都+1,次数累计到一个值后,读取完毕后删除这些数据,不知道
Storage类型及兼容
主要分为localStorage与sessionStorage,顾名思义,localStorage是没有时间限制的数据存储,sessionStorage是针对一个会话的数据存储。还有一个 globalStorageglobalStorage,不是Storage的实例,而是StorageObsolete的一个实例。,非标准接口,很多浏览器也不再支持,还是不要用的好.
当然,不是所有浏览器都支持storage的,移动版支持性能还不明,0pera HD版上是支持的,但电脑端支持情况如下:
| Storage(Desktop) | Chrome | Firefox (Gecko) | IE | Opera | Safari (WebKit) |
| localStorage | 4 | 3.5 | 8 | 10.50 | 4 |
| sessionStorage | 5 | 2 | 8 | 10.50 | 4 |
| globalStorage | 未实现 | 2-13 | 未实现 | 未实现 | 未实现 |
从上面的表格可以看到,这个新属性对于IE8以下并没有什么用,如果你想要去兼容IE8以下版本的话,在使用前,要判断一下是否支持storage属性,然后用cookie来实现。之后我们会附上方法。先来看看怎么使用Storage。
Storage使用
使用前先检测一下浏览器是不是能支持storage,可以使用特征检查。如下:
window.localStorage&&window.localStorage.getItemStorage被定义在WhatWG Storage Interface 中,如下:
interface Storage {
readonly attribute unsigned long length;
[IndexGetter] DOMString key(in unsigned long index);
[NameGetter] DOMString getItem(in DOMString key);
[NameSetter] void setItem(in DOMString key, in DOMString data);
[NameDeleter] void removeItem(in DOMString key);
void clear();
};对应的使用方法为:
- length:只读属性,本地存储数据的个数
- key(i): 获得第i个数据的值
- getItem(key): 得到字段为key的值
- setItem(key, value):向key字段中写入值value
- removeItem(key): 从本地数据中移除key字段
- clear(): 清除同一个域下的所有数据
注意:storage和cookie一样,以键值对的方式存储数据。在存储数据前,不管value值是什么类型,都会被toString方法转化成字符串存储,一般的做法都是使用浏览器提供的JSON或者是序列化方法来存取对象。
举个例子:
var ls=localStorage;
var data={
user:"John",
sex:"female"
};
ls.setItem('data',data);
ls.setItem('realData',JSON.stringify(data));
console.info(ls.data); //[object Object]
console.info(ls.realData); //{"user":"John","sex":"female"}不支持Storge怎么办
对于IE6和IE7,也可以使用userData,最多提供1024kb的空间,并且可以设置有效期,但是仍然存在写满报错的问题,并且userData创建的存储文件不能被枚举,因此需要人为地维护。 另外还可以使用内嵌flash控件,使用flash的本地存储空间,flash默认提供100kb,使用更多需要用户授权。
下面给大家介绍一个办法,使用cookie模拟Storage的操作,来自MDN官网,亲测好使
if (!window.localStorage) {
window.localStorage = {
getItem: function (sKey) {
if (!sKey || !this.hasOwnProperty(sKey)) { return null; }
return unescape(document.cookie.replace(new RegExp("(?:^|.*;\\s*)" + escape(sKey).replace(/[\-\.\+\*]/g, "\\$&") + "\\s*\\=\\s*((?:[^;](?!;))*[^;]?).*"), "$1"));
},
key: function (nKeyId) { return unescape(document.cookie.replace(/\s*\=(?:.(?!;))*$/, "").split(/\s*\=(?:[^;](?!;))*[^;]?;\s*/)[nKeyId]); },
setItem: function (sKey, sValue) {
if(!sKey) { return; }
document.cookie = escape(sKey) + "=" + escape(sValue) + "; path=/";
this.length = document.cookie.match(/\=/g).length;
},
length: 0,
removeItem: function (sKey) {
if (!sKey || !this.hasOwnProperty(sKey)) { return; }
var sExpDate = new Date();
sExpDate.setDate(sExpDate.getDate() - 1);
document.cookie = escape(sKey) + "=; expires=" + sExpDate.toGMTString() + "; path=/";
this.length--;
},
hasOwnProperty: function (sKey) { return (new RegExp("(?:^|;\\s*)" + escape(sKey).replace(/[\-\.\+\*]/g, "\\$&") + "\\s*\\=")).test(document.cookie); }
};
window.localStorage.length = (document.cookie.match(/\=/g) || window.localStorage).length;
}(PS:今天晚上在餐馆吃饭的时候碰到一个超帅的男生,聊了两句眼睛放亮啊,一整个晚上心情都超好)
学习笔记(一)之DOM空白符,window.getComputedStyle获取样式表
这几天做项目的时候,感觉重新学了一遍html,js,css啊,受益匪浅,将几个比较深刻的记录下来
1.DOM中的空白符
问题说明
DOM中的空白符真的是非常可恶啊,处理节点时增加不少麻烦,在你很high的用var a= element.nextSibling的时候,发现,咦!怎么不对啊,一打印出来才发现这是个:’#text’,尼玛,什么鬼,完全不是我们想要的啊。
在Mozilla的软件中,原始文件里所有的空白符都会在DOM中出现(不包括标签中的空白符)。这样处理有好有坏,好处是:编辑器里可以调整文字排列,css中的white-space: pre也可以发挥作用。但另一方面,这意味着:
- 有些空白符会自成一个文本节点
- 有些会与其他文本节点合成为一个文本节点
比如,下面这段HTML代码的DOM结构会变成图示样子
<!-- My document -->
<html>
<head>
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>
Paragraph
</p>
</body>
</html>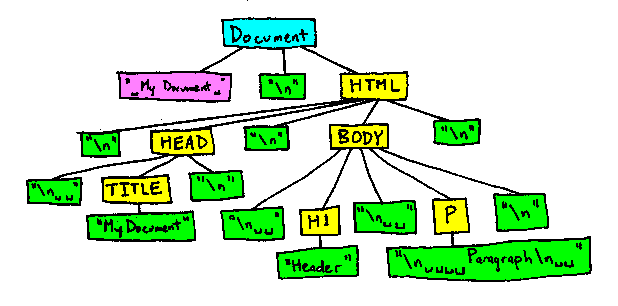
所以我们在进行节点操作的时候要忽略这些空白节点,首先知道空白符有哪些:
- ‘\t’ TAB \u0009 制表符
- ‘\n’ LF \u000A 换行符
- ‘\r’ CR \u000D 回车符
- ” ” SPC \u0020 空格符
现在我们可以用正则表达式来检测节点的内容里是不是空白符/[^\t\n\r ]/.test(node.data)
这里还要使用一个nodeType的属性,nodeType有以下几种取值:
| 常量名 | 值 |
| ELEMENT_NODE | 1 |
| ATTRIBUTE_NODE | 2 |
| TEXT_NODE | 3 |
| CDATA_SECTION_NODE | 4 |
| ENTITY_REFERENCE_NODE | 5 |
| ENTITY_NODE | 6 |
| PROCESSING_INSTRUCTION_NODE | 7 |
| COMMENT_NODE | 8 |
| DOCUMENT_NODE | 9 |
| DOCUMENT_TYPE_NODE | 10 |
| DOCUMENT_FRAGMENT_NODE | 11 |
| NOTATION_NODE | 12 |
解决办法
以element.nextSilbling为例,获得其真正意义上的下一节点
/**
* 测知某节点的文字内容是否全为空白。
*
* @参数 nod |CharacterData| 类的节点(如 |Text|、|Comment| 或 |CDATASection|)。
* @传回值 若 |nod| 的文字内容全为空白则传回 true,否则传回 false。
*/
function is_all_ws( nod )
{
// Use ECMA-262 Edition 3 String and RegExp features
return !(/[^\t\n\r ]/.test(nod.data));
}
/**
* 测知是否该略过某节点。
*
* @参数 nod DOM1 |Node| 对象
* @传回值 若 |Text| 节点内仅有空白符或为 |Comment| 节点时,传回 true,
* 否则传回 false。
*/
function is_ignorable( nod )
{
return ( nod.nodeType == 8) || // 注释节点
( (nod.nodeType == 3) && is_all_ws(nod) ); // 仅含空白符的文字节点
}
/**
* 此为会跳过空白符节点及注释节点的 |nextSibling| 函数
* @参数 sib 节点。
* @传回值 有两种可能:
* 1) |sib| 的下一个“非空白、非注释”节点。
* 2) 若该节点本身就是“非空白、非注释”节点
* 或者后无任何此类节点,则传回 null。
*/
function node_after( sib )
{
if(!!sib){
while ((sib = sib.nextSibling)) {
if (!is_ignorable(sib)) return sib;
};
};
return null;
}获得元素的应用样式表
问题描述
一次在js中用element.style的时候,发现获取不到在css里定义的某些属性,查找之后发现了另外一个方法window.geiComputedStyle(element[, pseudoElt]),还有document.defaultView.getComputedStyle(element[, pseudoElt]),element.currentStyle,下面说说这几个方法的区别:
方法对比
element.style:获得元素的内联样式,比如你可能给一个列表这么写li:nth-child(even){background-color: #fff},用这个函数就没办法获得背景色,并且该函数可读可写,用这个更改样式还是比较不错的window.getComputedStyle(Element,[, pseudoElt]):只能用来读取样式表,返回的样式是一个CSSStyleDeclaration 对象。这个函数会找到最终应用到元素上的所有样式,包括从父元素继承过来的元素balabala…值得一提的是,这个函数可以配合伪类一起使用(比如::after::before::marker)。getComputedStyle 在1.9.2 开始支持(Firefox 3.6 / Thunderbird 3.1 / Fennec 1.0).getComputedStyle的第一个参数必须是element对象,否则会报错document.defaultView.getComputedStyle:作用和使用都与第二个差不多,很多库都是通过document.defaultView来调用getComputedStyle,比如JQuery,看MDN文档上说,一般都不需要这样,window直接调用就可以,只有一种情况,在Firefox3.6上访问子框架内的样式需要使用该方法element.currentStyle:这个是IE自己搞的一个方法,使用形式和element.Style类似,不过这个方法返回的也是该元素最终应用到元素上的所有样式,包括外链的CSS样式啥的,不过不支持伪类
兼容性
| getComputedStyle(桌面版) | Chrome | Firefox (Gecko) | IE | Opera | Safari |
| 基本支持 | yes | yes | 9 | yes | yes |
| 伪元素支持 | yes | yes | 11 | 未实现 | yes |
| getComputedStyle(手机版) | Android | Firefox Mobile(Gecko) | IE Mobile | Opera Mobile | Safari |
| 基本支持 | yes | yes | WP7 Mango | yes | yes |
| 伪元素支持 | ? | ? | 未实现 | 未实现 | ? |
使用方法
var ele= document.getElementById('t');
var style=ele.currentStyle?ele.currentStyle:window.getComputedStyle(ele, null);东西太多了,明天再继续写吧~
文本溢出显示省略号总结
1.单行文本溢出显示
大家都知道有这么个属性text-overflow:ellipsis用来实现单行文本的文本溢出显示省略号,当然,在一般浏览器中还要设置width属性,举例说明:
2.多行文本溢出显示
1.Webkit浏览器或移动端
在webkit为内核的浏览器或移动端(绝大部分是webkit内核的浏览器)的页面实现比较简单,可以直接使用似有的css扩展属性-webkit-line-clamp,该属性的作用是用来限制块元素显示文本的行数,使用时还要结合其他属性,如下:
display: -webkit-box:将对象作为弹性伸缩盒子显示,必须使用-webkit-box-orient:设置或检索子元素的排列方式,必须使用text-overflow:ellipsis:多行文本的情况下,设置显示方式 使用例子: <iframe width="100%" height="300" src="//jsfiddle.net/donqi/j2do1o9o/embedded/result,css,html,js/" allowfullscreen="allowfullscreen" frameborder="0"></iframe>
2.使用::after伪元素实现
这个办法可以跨浏览器兼容,使用::after伪元素在文本后添加一个省略号(…),看起来效果是还可以的 使用例子: <iframe width="100%" height="300" src="//jsfiddle.net/donqi/dgeLb9qy/2/embedded/result,css,html,js/" allowfullscreen="allowfullscreen" frameborder="0"></iframe>
小提示:
::after伪元素里的内容是用绝对定位的,因此,其父元素一定要设置为display:relative/absolute- 注意设置文本的高度,使其正常显示,总体高度最好是单行的整数倍。
- 注意要给
::after的内容添加一个背景色,可以父元素的背景色一样,也可以用一个渐变色做背景,效果更好(PS:我的例子透明度还不太恰当,可以再调) - IE8中要将
::after改为:after,IE6.7中不能显示content的内容,需在内容中加入一个标签,比如…
3.JS模拟实现
1.Clamp.js
下载地址:https://github.com/josephschmitt/Clamp.js
使用示例:
1 var module = document.getElementById("clamp-this-module");
2 $clamp(module, {clamp: 2});2.JQuery.dotdotdot
下载地址:https://github.com/BeSite/jQuery.dotdotdot或http://dotdotdot.frebsite.nl/
使用方法:
1 $(document).ready(function(){
2 $("#wrapper").dotdotdot({
3 //configuration here
4 });
5 });参考资料:
Jekyll使用时遇到的各种小问题
图片路径异常
1.问题描述
在博客中插入图片,在首页上是显示正常的,但是到了其他页面(比如归档页面)却没办法正常显示,图片插入方式如下:
<img title="黄殷琪" src="/images/aboutme.jpg" alt="黄殷琪"/>_config.yml中的相关部分定义如下:
aboutme_photo: images/aboutme.jpg2.问题解决
在主页时,查看图片路径,正常;进到关于页面时,图片路径出错。原来是进入该页面时,所有的文章都进入到相应的目录下比如about/index.html,而我把图片的路径设置为了相对路径,那么图片的路径也就会变成about/image/aboutme_photo.jpg,因此出错。
只要把路径改为绝对路径,即相对于blog的根目录的路径:aboutme_photo: /images/aboutme.jpg
jekyll在windows下中文编码报错
1.问题描述
用jekyll写一个之前已经写了一半的页面时,编译时发现编码报错,这是搞什么鬼啊啊啊,仔细想过之后找到了问题所在,之前写的时候是拿sublime写的,这回为了方便就直接用记事本写的,记事本的默认编码是ASNI的啊,我之前设置的jekyll读取本地文件的方式是UTF-8,因此出现了问题.
2.问题解决:
1.先找到一个文件,文件名是convertible.rb,路径一般是:D:\jekyll\ruby\Ruby21\lib\ruby\gems\2.1.0\gems\jekyll-2.5.3\lib\jekyll ,
修改里面的这句话:
self.content = File.read_with_options(File.join(base, name), merged_file_read_opts(opts))
改为:
self.content = File.read(File.join(base, name),:encoding=>"utf-8")2.编辑代码的时候注意编辑器的编码格式,要和之前的设置保持一致,不然读取出错,如果是特别喜欢用记事本的话,可以参照这个修改=.=http://blog.csdn.net/cenziboy/article/details/7341923
ruby编译scss出现invalid GBK错误
问题描述:
在windows7上面,通过ruby编译scss时,发现编译报错,内容如下:
Conversion error: Jekyll::Converters::Scss encountered an error while converting 'css/main.scss':
Invalid GBK character "\xE3" on line 315虽然给出来了报错的原因,但是尼玛,main.scss总共也没有315行啊,而且并没有中文注释什么的。查找一番之后才发现,这里编译器报错的位置不一定是scss中的位置,也有可能是你在scss中引用了其他库中含有中文字符。我在scss中引入了字体文件,文件中包含了中文字符
解决办法:
1.在ruby的安装目录下找到engine.rb文件,目录格式如 D:\ruby\Ruby21\lib\ruby\gems\2.1.0\gems\sass-3.4.15\lib\sass在文件中添加一行Encoding.default_external = Encoding.find('utf-8') 在require语句结束处,如:
require 'sass/media'
require 'sass/supports'
module Sass
Encoding.default_external = Encoding.find('utf-8')2.在scss文件的头部加一行@charset “utf-8”
