学习笔记(一)之DOM空白符,window.getComputedStyle获取样式表
这几天做项目的时候,感觉重新学了一遍html,js,css啊,受益匪浅,将几个比较深刻的记录下来
1.DOM中的空白符
问题说明
DOM中的空白符真的是非常可恶啊,处理节点时增加不少麻烦,在你很high的用var a= element.nextSibling的时候,发现,咦!怎么不对啊,一打印出来才发现这是个:’#text’,尼玛,什么鬼,完全不是我们想要的啊。
在Mozilla的软件中,原始文件里所有的空白符都会在DOM中出现(不包括标签中的空白符)。这样处理有好有坏,好处是:编辑器里可以调整文字排列,css中的white-space: pre也可以发挥作用。但另一方面,这意味着:
- 有些空白符会自成一个文本节点
- 有些会与其他文本节点合成为一个文本节点
比如,下面这段HTML代码的DOM结构会变成图示样子
<!-- My document -->
<html>
<head>
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>
Paragraph
</p>
</body>
</html>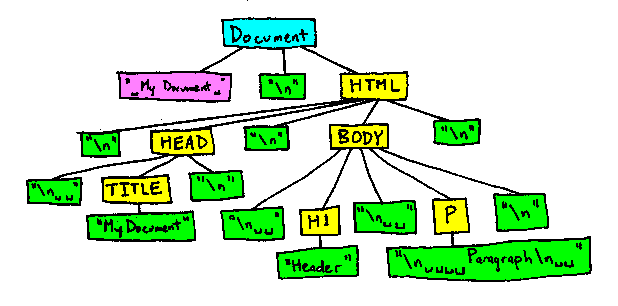
所以我们在进行节点操作的时候要忽略这些空白节点,首先知道空白符有哪些:
- ‘\t’ TAB \u0009 制表符
- ‘\n’ LF \u000A 换行符
- ‘\r’ CR \u000D 回车符
- ” ” SPC \u0020 空格符
现在我们可以用正则表达式来检测节点的内容里是不是空白符/[^\t\n\r ]/.test(node.data)
这里还要使用一个nodeType的属性,nodeType有以下几种取值:
| 常量名 | 值 |
| ELEMENT_NODE | 1 |
| ATTRIBUTE_NODE | 2 |
| TEXT_NODE | 3 |
| CDATA_SECTION_NODE | 4 |
| ENTITY_REFERENCE_NODE | 5 |
| ENTITY_NODE | 6 |
| PROCESSING_INSTRUCTION_NODE | 7 |
| COMMENT_NODE | 8 |
| DOCUMENT_NODE | 9 |
| DOCUMENT_TYPE_NODE | 10 |
| DOCUMENT_FRAGMENT_NODE | 11 |
| NOTATION_NODE | 12 |
解决办法
以element.nextSilbling为例,获得其真正意义上的下一节点
/**
* 测知某节点的文字内容是否全为空白。
*
* @参数 nod |CharacterData| 类的节点(如 |Text|、|Comment| 或 |CDATASection|)。
* @传回值 若 |nod| 的文字内容全为空白则传回 true,否则传回 false。
*/
function is_all_ws( nod )
{
// Use ECMA-262 Edition 3 String and RegExp features
return !(/[^\t\n\r ]/.test(nod.data));
}
/**
* 测知是否该略过某节点。
*
* @参数 nod DOM1 |Node| 对象
* @传回值 若 |Text| 节点内仅有空白符或为 |Comment| 节点时,传回 true,
* 否则传回 false。
*/
function is_ignorable( nod )
{
return ( nod.nodeType == 8) || // 注释节点
( (nod.nodeType == 3) && is_all_ws(nod) ); // 仅含空白符的文字节点
}
/**
* 此为会跳过空白符节点及注释节点的 |nextSibling| 函数
* @参数 sib 节点。
* @传回值 有两种可能:
* 1) |sib| 的下一个“非空白、非注释”节点。
* 2) 若该节点本身就是“非空白、非注释”节点
* 或者后无任何此类节点,则传回 null。
*/
function node_after( sib )
{
if(!!sib){
while ((sib = sib.nextSibling)) {
if (!is_ignorable(sib)) return sib;
};
};
return null;
}获得元素的应用样式表
问题描述
一次在js中用element.style的时候,发现获取不到在css里定义的某些属性,查找之后发现了另外一个方法window.geiComputedStyle(element[, pseudoElt]),还有document.defaultView.getComputedStyle(element[, pseudoElt]),element.currentStyle,下面说说这几个方法的区别:
方法对比
element.style:获得元素的内联样式,比如你可能给一个列表这么写li:nth-child(even){background-color: #fff},用这个函数就没办法获得背景色,并且该函数可读可写,用这个更改样式还是比较不错的window.getComputedStyle(Element,[, pseudoElt]):只能用来读取样式表,返回的样式是一个CSSStyleDeclaration 对象。这个函数会找到最终应用到元素上的所有样式,包括从父元素继承过来的元素balabala…值得一提的是,这个函数可以配合伪类一起使用(比如::after::before::marker)。getComputedStyle 在1.9.2 开始支持(Firefox 3.6 / Thunderbird 3.1 / Fennec 1.0).getComputedStyle的第一个参数必须是element对象,否则会报错document.defaultView.getComputedStyle:作用和使用都与第二个差不多,很多库都是通过document.defaultView来调用getComputedStyle,比如JQuery,看MDN文档上说,一般都不需要这样,window直接调用就可以,只有一种情况,在Firefox3.6上访问子框架内的样式需要使用该方法element.currentStyle:这个是IE自己搞的一个方法,使用形式和element.Style类似,不过这个方法返回的也是该元素最终应用到元素上的所有样式,包括外链的CSS样式啥的,不过不支持伪类
兼容性
| getComputedStyle(桌面版) | Chrome | Firefox (Gecko) | IE | Opera | Safari |
| 基本支持 | yes | yes | 9 | yes | yes |
| 伪元素支持 | yes | yes | 11 | 未实现 | yes |
| getComputedStyle(手机版) | Android | Firefox Mobile(Gecko) | IE Mobile | Opera Mobile | Safari |
| 基本支持 | yes | yes | WP7 Mango | yes | yes |
| 伪元素支持 | ? | ? | 未实现 | 未实现 | ? |
使用方法
var ele= document.getElementById('t');
var style=ele.currentStyle?ele.currentStyle:window.getComputedStyle(ele, null);东西太多了,明天再继续写吧~
